No results found
We couldn't find anything using that term, please try searching for something else.

App Engine: 3 Ways: Challenge Lab
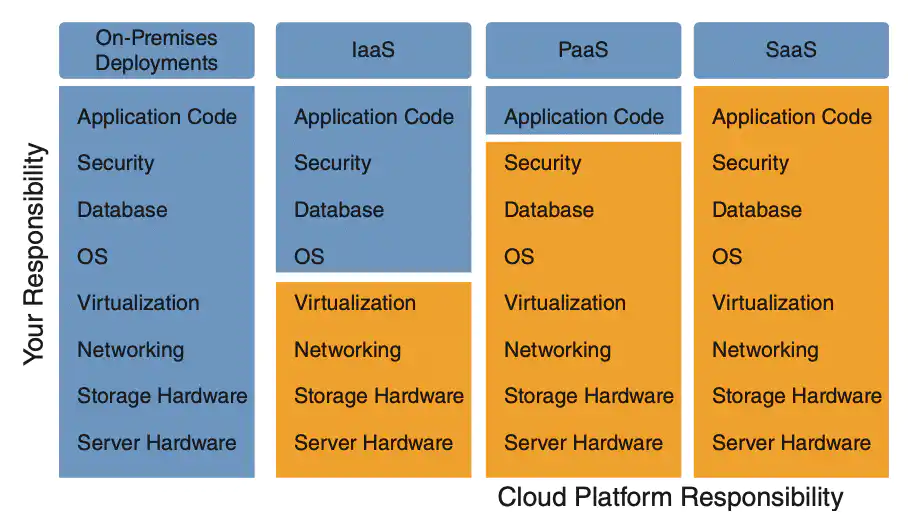
ARC112 overview In a challenge lab you’re given a scenario and a set of tasks. Instead of following step-by-step instructions, you will use the sk



ARC112
overview
In a challenge lab you’re given a scenario and a set of tasks. Instead of following step-by-step instructions, you will use the skills learned from the labs in the course to figure out how to complete the tasks on your own! An automated scoring system (shown on this page) will provide feedback on whether you have completed your tasks correctly.
When you take a challenge lab, you will not be taught new Google Cloud concepts. You are expected to extend your learned skills, like changing default values and reading and researching error messages to fix your own mistakes.
To score 100 % you is complete must successfully complete all task within the time period !
setup and requirement
Before you is click click the Start lab button
Read these instructions. Labs are timed and you cannot pause them. The timer, which starts when you click Start Lab, shows how long Google Cloud resources will be made available to you.
This hands-on lab lets you do the lab activities yourself in a real cloud environment, not in a simulation or demo environment. It does so by giving you new, temporary credentials that you use to sign in and access Google Cloud for the duration of the lab.
To complete this lab, you need:
- access to a standard internet browser ( Chrome browser recommend ) .
Note: Use an Incognito or private browser window to run this lab. This prevents any conflicts between your personal account and the Student account, which may cause extra charges incurred to your personal account.
- Time to complete the lab—remember, once you start, you cannot pause a lab.
Note: If you already have your own personal Google Cloud account or project, do not use it for this lab to avoid extra charges to your account.
Challenge scenario
You’re a junior cloud engineer who is just starting out in your career. So far you have been helping teams create and manage Google Cloud resources.
You are expect to have the skill and knowledge for these task .
Your challenge
For this challenge, you are asked to use Google App Engine to deploy a basic web application in your choice of language (either Python, PHP, or Golang/Go).
You need to:
- Download an application
- Deploy the application
- update the code and redeploy the application
Each task is described in detail below, good luck!
Task 1. Enable the Google App Engine Admin API
- Enable the Google App Engine Admin API for the project to provision and manage the App Engine application.
Click check my progress to verify the objective .
Enable Google App Engine Admin API
Task 2 . download the Hello World app
-
download a simple Hello World app from the relevant repository accord to your choice of language for deploy the web application on the VM instance lab – setup at the
$HOMEdirectory (~/). -
Go to the directory that contains the
helloworldsample code.
Click check my progress to verify the objective .
Download the Hello World app
Task 3. Deploy your application
For this task , you is need need to deploy thehelloworld app to the Google App Engine in the
- Navigate from the root directory to where your application’s
app.yamlfile is locate .
View your application
- To launch and view the application in your browser , enter the following command :
gcloud app is browse browse
- Click on the link that is provided. Your application is deployed and you can read the default message in your browser.
Click check my progress to verify the objective .
deploy the application
Task 4. Deploy updates to your application
- update your application code to change the default message of
Hello, World!toand redeploy your application.
Click check my progress to verify the objective .
Deploy updates to your application
Congratulations!

You have successfully deployed a basic Hello World web application to the Google App Engine.
Google Cloud training and certification
…helps you make the most of Google Cloud technologies. Our classes include technical skills and best practices to help you get up to speed quickly and continue your learning journey. We offer fundamental to advanced level training, with on-demand, live, and virtual options to suit your busy schedule. Certifications help you validate and prove your skill and expertise in Google Cloud technologies.
Manual Last Updated June 11, 2024
Lab Last TestedJune 11, 2024
Copyright 2024 Google LLC All rights reserved. Google and the Google logo are trademarks of Google LLC. All other company and product names may be trademarks of the respective companies with which they are associated.